Data-Efficient Reinforcement Learning in Continuous State-Action Gaussian-POMDPs
Data-Efficient Reinforcement Learning in Continuous State-Action Gaussian-POMDPs
Abstract
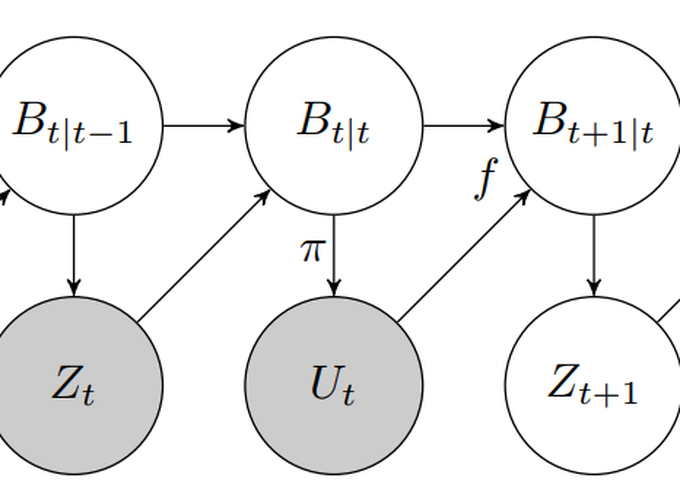
We present a data-efficient reinforcement learning method for continuous stateaction systems under significant observation noise. Data-efficient solutions under small noise exist, such as PILCO which learns the cartpole swing-up task in 30s. PILCO evaluates policies by planning state-trajectories using a dynamics model. However, PILCO applies policies to the observed state, therefore planning in observation space. We extend PILCO with filtering to instead plan in belief space, consistent with partially observable Markov decisions process (POMDP) planning. This enables data-efficient learning under significant observation noise, outperforming more naive methods such as post-hoc application of a filter to policies optimised by the original (unfiltered) PILCO algorithm. We test our method on the cartpole swing-up task, which involves nonlinear dynamics and requires nonlinear control.
Rowan McAllister
Senior Manager
My research interests include autonomous vehicles, reinforcement learning, and probabilistic modelling.